INGENIERÍA
ITIANOS
3ro
ITIANOS
TSU
4to
Ingeniería
7mo
DBD-ES
Las bases de datos hoy en día han cobrado una importancia muy alta dentro de una empresa ya que es ahí donde residen todos los datos operacionales y funcionales de la misma.
El alumno será capaz de aplicar los conocimientos fundamentales teóricos y prácticos en el funcionamiento de los sistemas de bases de datos y el planteamiento de modelos de datos que describen problemas reales para implementar dichos modelos usando DBMS „s relacionales.
Las bases de datos hoy en día han cobrado una importancia muy alta dentro de una empresa ya que es ahí donde residen todos los datos operacionales y funcionales de la misma.
La asignatura Diseño de Bases de Datos, tiene como propósito que el alumno sea capaz de aplicar los conocimientos fundamentales teóricos y prácticos en el funcionamiento de los sistemas de bases de datos y el planteamiento de modelos de datos que describen problemas reales para implementar dichos modelos usando DBMS „s relacionales.
El contenido de esta asignatura consta de cinco unidades las cuales son: 1) Modelos de datos y modelado conceptual. 2) Técnicas de análisis y diseño de bases de datos. 3) Metodología, 4) Modelado estandarizado e 5) Integración de datos.
1. Almacén de Datos. Llamado Data Warehouse, es una gran colección de datos que recoge información de múltiples sistemas fuentes u operacionales dispersos.
2. Atributos. Son las propiedades que describen las características de una entidad.
3. Base de datos. Llamado banco de datos, es un conjunto de datos que pertenecen al mismo contexto, almacenados sistemáticamente para su posterior uso.
4. Base de datos de red. Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico). Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.
5. Bases de datos de texto completo. Almacenan las fuentes primarias, como por ejemplo, todo el contenido de todas las ediciones de una colección de revistas científicas.
6. Bases de datos dinámicas. Éstas son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización y adición de datos, además de las operaciones fundamentales de consulta. Un ejemplo de esto puede ser la base de datos utilizada en un sistema de información de una tienda de abarrotes, una farmacia, un videoclub, etc.
7. Bases de datos estáticas. Son de sólo lectura, utilizadas primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones y tomar decisiones.
8. Bases de datos jerárquicas. Son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento. Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
9. Bases de datos orientadas a objetos. Este modelo, bastante reciente, y propio de los modelos informáticos orientados a objetos, trata de almacenar en la base de datos los objetos completos (estado y comportamiento). Incorpora todos los conceptos importantes del paradigma de objetos: encapsulación, herencia y polimorfismo.
10. Base de datos relacional. En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos. La información puede ser recuperada o almacenada mediante "consultas" que ofrecen una amplia flexibilidad y poder para administrar la información. El lenguaje más habitual para construir las consultas a bases de datos relacionales es SQL, Structured Query Language o Lenguaje Estructurado de Consultas.
11. Entidad. Objeto del mundo real sobre el que queremos almacenar información.
12. Entidad débil. Depende de la existencia de otra llamada entidad fuerte.
13. Estándar. Patrón uniforme o muy generalizado de una cosa.
14. Herramientas CASE (Computer Aided Software Engineering, Ingeniería de Software Asistida por Computadora). Son diversas aplicaciones informáticas destinadas a aumentar la productividad en el desarrollo de software reduciendo el coste de las mismas en términos de tiempo y de dinero.
15. Identificador. Ayuda a validar o reconocer una instancia o valor dentro de una serie de valores.
16. Lenguaje de Definición de Datos o DDL (Data Definition Language). Su función es describir, de una forma abstracta, las estructuras de datos y las restricciones de integridad.
17. Lenguaje de Manipulación de Datos o DML (Data Manipulation Language). Se orienta a describir las operaciones de manipulación de los datos.
18. Lenguaje de Modelado Unificado (UML). Es un lenguaje para la especificación, visualización, construcción y documentación de los artefactos de un proceso de sistema intensivo.
19. Lenguaje de transformación. Permite definir patrones de transformación entre los metamodelos y establecer las correspondencias entre el metamodelo fuente y el metamodelo destino.
20. Mercados de dato. Llamado Data Mart, es una versión especial de almacén de datos (data warehouse). Como los almacenes de datos, los data marts contienen una visión de datos operacionales que ayudan a decidir sobre estrategias de negocio basadas en el análisis de tendencias y experiencias pasadas.
21. Metamodelo. Mecanismo que permite la definición formal de modelos.
22. Model Driven Architecture (MDA). Consiste en un conjunto de estándares que asisten en la creación, implementación, evolución y desarrollo de sistemas dirigido por modelos.
23. Modelo. Es una descripción parcial o total de un sistema escrito en un lenguaje de modelado.
24. Modelo de datos. Es básicamente una "descripción" de algo conocido como contenedor de datos (algo en donde se guarda la información), así como de los métodos para almacenar y recuperar información de esos contenedores. Los modelos de datos no son cosas físicas: son abstracciones que permiten la implementación de un sistema eficiente de base de datos; por lo general se refieren a algoritmos, y conceptos matemáticos.
25. Modelos de datos conceptuales. Son aquellos que describen las estructuras de datos y restricciones de integridad. Se utilizan durante la etapa de análisis de un problema dado y están orientados a representar los elementos que intervienen y sus relaciones.
26. Modelos de datos físicos. Son estructuras de datos a bajo nivel implementadas dentro del propio manejador.
27. Modelos de datos lógicos. Se centran en las operaciones y se implementan en algún manejador de base de datos.
28. Modelo Entidad-Relación (E-R). Es uno de los ejemplos más populares de los modelos de datos conceptuales.
29. Relación. Asociación entre entidades, sin existencia propia en el mundo real que se está modelando, pero necesaria para reflejar las interacciones existentes entre entidades.
30. SQL, Structured Query Language o Lenguaje Estructurado de Consultas. Un estándar implementado por los principales motores o sistemas de gestión de bases de datos relacionales.
En la plataforma Moodle se habilitará una liga para subir las tareas, prácticas y evaluaciones, con un tiempo determinado.
| HORA | LUNES | MARTES | MIÉRCOLES | JUEVES | VIERNES |
|---|---|---|---|---|---|
| 7:30-8:20 | |||||
| 8:20-9:10 | X | ||||
| 9:10-10:00 | |||||
| 10:00-10:50 | |||||
| 10:50-11:40 | |||||
| 11:40-12:30 | X NP | ||||
| 12:30-13:20 | X NP | X | |||
| 13:20-14:10 | X | X | X |
1. Sistemas de base de datos Thomas M. Connolly, Carolyn E. Begg 2007 Pearson, Addison Wesley España,2007 84-7829-075-3
2. Introducción a las bases de datos: el modelo relacional Olga Pons Capote, Nicolás Marín, Juan Miguel Medina, Silvia Acid, Ma. Amparo Vila 2007 Thomson España, 2007 8497323963
3. Fundamentos de Sistemas de Base de Datos Ramez Elmasri y Shamkant B. Nathe 2007 Pearson, Addison Wesley España, 2007 978-84-7829-085-7
4. Tecnología y Diseño de Bases de Datos Piattini Velthuis, Mario G., 2007 Ra-Ma España, 2007 8478977333
5. Diseño de bases de datos Stephens, Rod. 2007 Wrox, Programer España, 2007 8441525781
6. Fundamentos de bases de datos Silberschatz, Abraham, Henry F. Korth, S. Sudarshan 40 2007 McGraw-Hill Madrid, 2007 84-481-0079-4
7. Departamento de Lenguajes y Sistemas Informáticos. ( ) Diseño de bases de datos [ ], ( ). Disponible en: http://www.lsi.us.es/docencia/get.php?id=5427 Consultado el 02 de octubre de 2011.
8. Escuela Universitaria de Informática. () Modelos de datos [ ], ( ). Disponible en: http://bd.eui.upm.es/BD/docbd/tema/tema2.pdf Consultado el 11 de octubre de 2011.
9. González Jaime. (1998) El discreto encanto del metamodelo de UML [ ], ( ). Disponible en: http://www.zeusconsult.com.mx/DISCRET.pdf Consultado el 19 de octubre de 2011.
El mundo de los sistemas de BD
Hoy en día las BD son escenciales en los negocios. Miles de sitios tienen una BD atrás de las pantallas y los escenarios que vez. También las BD son el centro de miles de investigaciones.
El poder de una BD proviene de la tecnología desarrollada en diferentes décadas y toda esta envuelta en sistema gestor de base de datos.
¿Qué es una Base de Datos?
Es una colección de información que existe durante un largo periodo de tiempo, organizada y almacenada. Ej. Los registros de una biblioteca, control de clientes, etc.
Definición de Datos
Los datos son los hechos que describen suscesos y entidades. Los datos son comunidacos por varios tipos de símbolos tales como las letras del alfabeto, números, movimientos de labios, puntos y rayas, señales con la mano, dibujos, etc.
Definición de información
Es un conjunto de datos significativos y pertinentes que describen sucesos o entidades.
Datos significativos
Para ser significativos, los datos deben constar de símbolos reconocibles, estar completos y expresar una idea no ambigua.
Datos pertinentes
Decimos que tenemos datos pertinentes (relevantes) cuando pueden ser utilizados para responder a preguntas propuestas.
¿Qué es un sistema gestor de base de datos (SGBD o DBMS)?
(DataBase Management System) Es un software que permite organizar datos. Es una capa que se sitúa por encima del sistema operativo.
Ejemplos de SGBD:
Hay 2 tipos de uso de un SGBD
Lenguajes de comandos para interactuar con un SGBD
Objetivo de una BD
Organizar los datos de modo que sea sencillo acceder a ellos.
Características de BD
Sistemas de ficheros vs SGBD
Los objetivos de los SGBD fueron apareciendo históricamente con el fin de superar los problemas que daba trabajar directamente con ficheros. Problemas que tenían los sistemas de ficheros y que resuelven los SGBD:
Arquitectura ANSI/SPARC
ANSI es un comité que estableció que un SGBD tenía que permitir que los datos fuesen vistos con distintos niveles de abstracción por distintos profesionales:
Independencia lógica
Se tiene que poder modificar la estructura de los ficheros sin que los programas dejen de funcionar. Las bases de datos pueden soportar eso del mismo modo que soportan la independencia física. el programador no tiene que hacer referencia a la estructura completa (sólo referencia a los campos que necesita) y no tiene que conocer el tamaño de los campos.
Ventaja: No es necesario modificar los programas si se modifican los registros de los ficheros. El administrador es el que le dice al SGBD los cambios que haya en cuanto a la ubicación de ficheros y estructura de los mismos.
Historia de los SGBD
Uno de los primeros SGBD fue IMS y lo sacó al mercado IBM (IMS fue el primero que cumple con todas las características de un SGBD). IMS tenía DDL y DML.
Poco después apareció un sistema denomidando CODASYL que, al igual que IMS, tuvo una serie de imitadores.
Había dos grandes filosofías de un SGBD:
Empresas donde se usan las BD:
Modelo de Datos
Es una colección de heramientas conceptuales para la descripción de datos, relacionales entre datos, semántica de los datos y restricciones de consistencia.
Tipos de modelos de datos
Las personas que trabajan con una base de datos se pueden clasificar como:
Tipos de DB Users
DBA
Es la persona que tiene un control centralizado tanto de los SGBD como de los programas que tienen acceso a esos datos. Sus funciones son:
Diseño de bases de datos
Los sistemas de BD se diseñan para gestionar grandes cantidades de información. El diseño de las bases de datos implica principalmente el diseño del esquema de las bases de datos.
Proceso de diseño
Normalización
Su objetivo es generar un conjunto de esquemas relacionales que permita almacenar información sin redundancias innecesarias, pero que también permita recuperar la información con facilidad. El enfoque es diseñar esquemas que se hallen en la forma normal adecuada. Algunas propiedades no desables en el diseño de bases de datos son:
Minería y análisis de datos
El término MINERÍA DE DATOS (Data mining) se refiere en líneas generales al proceso de análisis semiautomático de grandes bases de datos para descubrir patrones útiles. "La minería de datos trata del descubrimiento de conocimiento en las bases de datos".
Modelo Entidad-Relación (definición)
Es un modelo basado en una percepción del mundo real que consiste en un conjunto de objetos básicos, denominados entidades y de las relaciones entre estos objetos.
Entidad (definición)
Es una "cosa" u "objeto" del mundo real que es distinguible de otros objetos. Por ejemplo, cada persona es una entidad, y las cuentas bancarias pueden considerarse entidades. Las entidades se describen mediante un conjunto de atributos. Por ejemplo los atributos de una cuenta de un banco son: número_cuenta, saldo.
Relación
Es una asociación entre varias entidades. Por ejemplo, la relación Alumnos cursan Materias, relaciona a los alumnos con materias.
Atributos
Describen propiedades que posee cada miembro de un conjunto de entidades. La designación de un atributo para un conjunto de entidades expresa que la base de datos almacena información similar conceriente a cada entidad del conjunto de entidades; sin embargo, cada entidad puede tener su propio valor para cada atributo.
Conjunto de entidades
Es un conjunto de entidades del mismo tipo que comparten las mismas propiedades, o atributos. El conjunto de todas las personas que son clientes en un banco dado, por ejemplo, se pueden definir como el conjunto de entidades cliente.

Conjunto de relaciones
Es un conjunto de relaciones del mismo tipo. Muchos registros de una entidad se relacionan con los registros de otra entidad.
Existen diferentes tipos de relaciones.

Dominio o conjunto de valores
Para cada atributo hay un conjunto de valores permitidos.
Tipos de atributos:
Existen:
Valores núlos
Es núlo cuando una entidad no tiene un valor para un atributo. También se puede aplicar el término "no aplicable", es decir, que el valor no existe para la entidad.

ACTIVIDAD 1 (en hojas de máquina): Representa por medio de rectángulos y eclipses las siguientes entidades y sus atributos: El ministerio de la salud desea mantener un sistema de información relativo a hospitales. A continuación se detalla lo que se desea modelar:
ACTIVIDAD 2 (en hojas de máquina): Elabora una base de datos para registrar la información de los clientes de una empresa: Los clientes tienen un nombre completo que se compone de nombre pila, primer apellido, segundo apellido, también pueden o no tener número de teléfono, fecha de nacimiento, edad y dirección compuesta por calle, ciudad, providencia y código postal. La calle se compone de número de calle, nombre de la calle y número de piso.
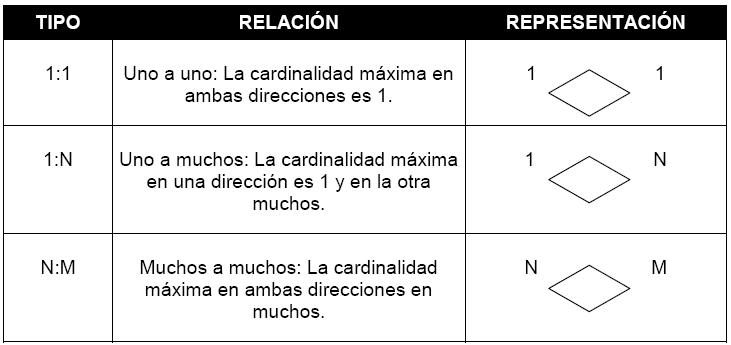
Un esquema de desarrollo E-R puede definir ciertas restricciones a las que los contenidos de la base de datos se deben adaptar. A continuación se examina la correspondencia de cardinalidades y las restricciones de participación, que son dos de los tipos más importantes de restricciones.
Correspondencia de cardinalidades
También llamada razón de cardinalidad, expresa el número de entidades a las que otra entidad puede estar asociada vía un conjunto de relaciones. La correspondencia de cardinalidades es la más útil describiendo conjuntos de relaciones binarias, aunque ocasionalmente contribuye a la descripción de conjuntos de relaciones que implican más de dos conjuntos de entidades. Para un conjunto de relaciones binarias R entre los conjuntos de entidades A y B, la correspondencia de cardinalidades debe ser una de las siguientes:




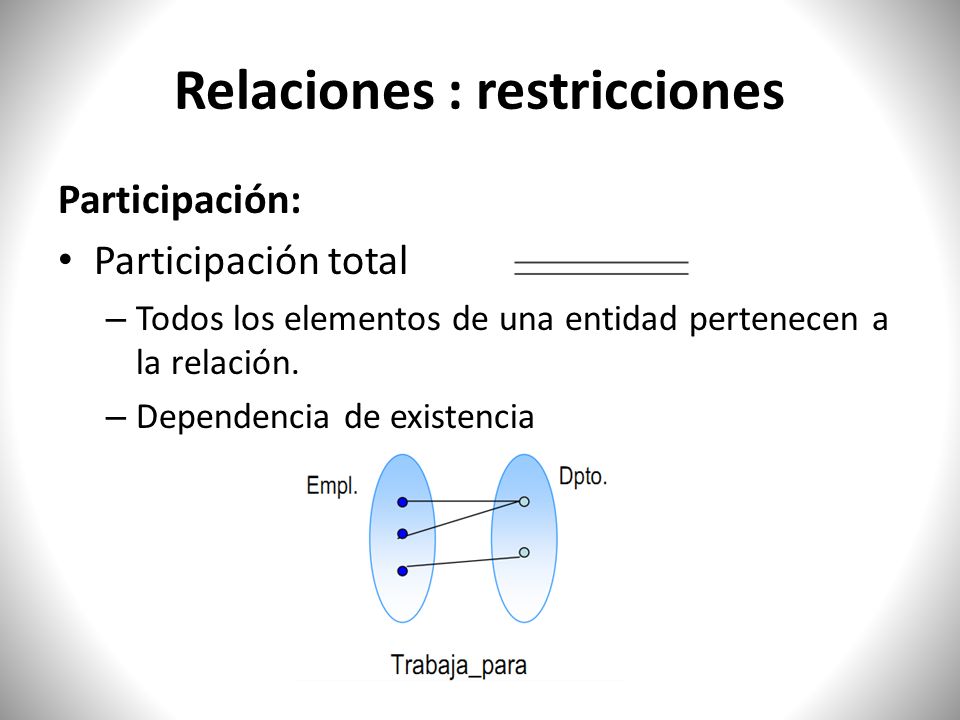
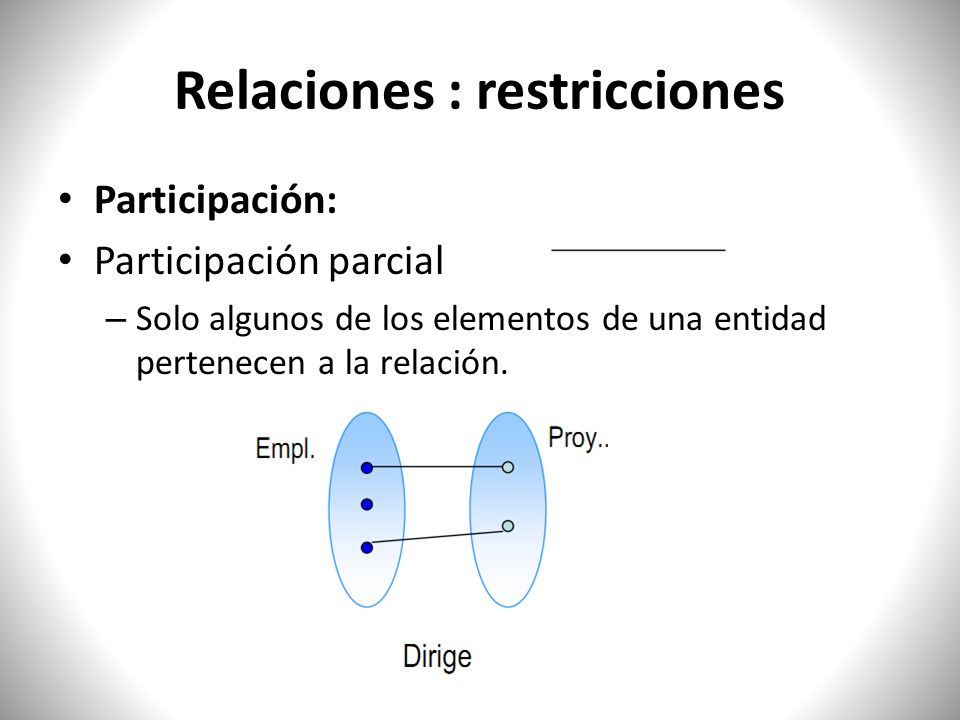
Restricciones de participación
La participación de un conjunto de entidades E en un conjunto de relaciones R se dice que es total si cada entidad E participa al menos en una relación en R. Si sólo algunas entidades de E participan en relaciones en R, la participación del conjunto de entidades de E en la relación R se llama parcial.
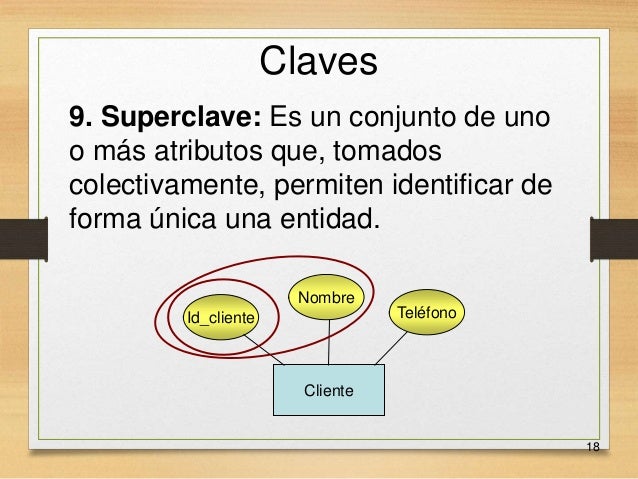
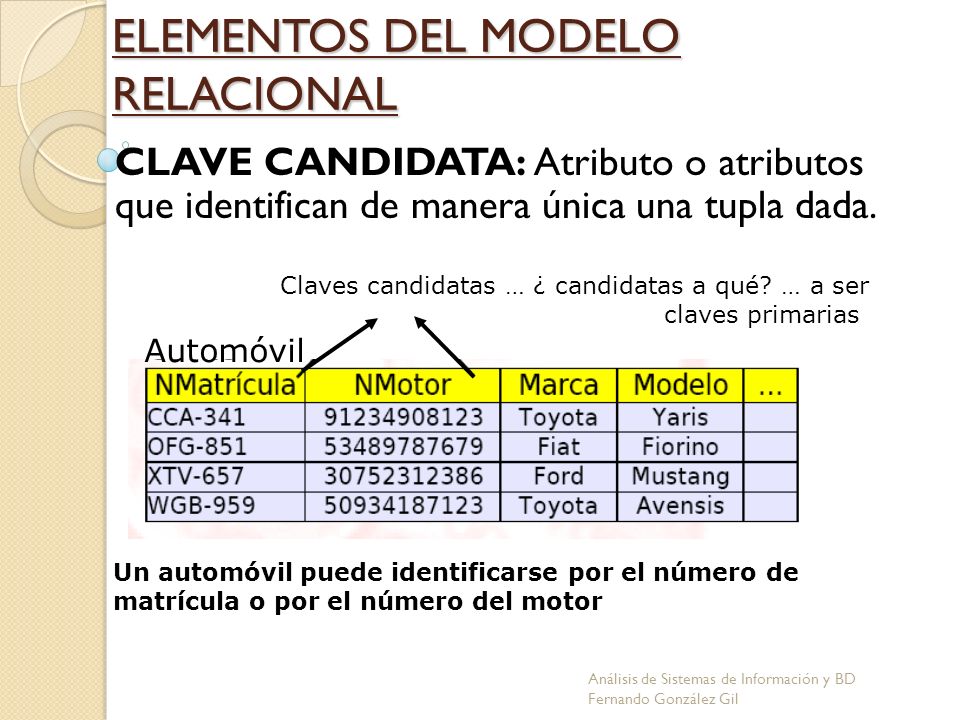
Claves
Es necesario tener una forma de especificar la manera de distinguir las entidades pertenecientes a un conjunto de entidades dado. Conceptualmente cada entidad es distinta; desde el punto de vista de las bases de datos, sin embargo, la diferencia entre ellas se debe expresar en términos de sus atributos.
Por lo tanto, los valores de los atributos de cada entidad deben ser tales que permitan identificar unívocamente a esa entidad. En otras palabras, no se permite que ningún par de entidades de un conjunto de entidades tenga exactamente el mismo valor en todos sus atributos.
Claves
Las claves permiten identificar un conjunto de atributos que resulta suficiente para distinguir las entidades entre sí. Las claves también ayudan a identificar unívocamente las relaciones y, por tanto, a distinguir las relaciones entre sí.


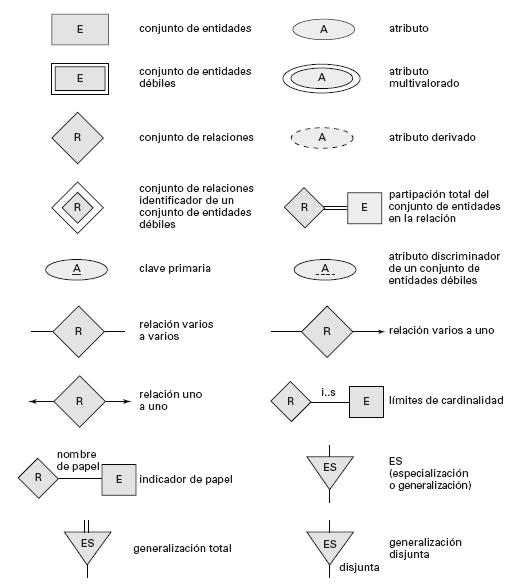
Cuando una entidad participa en una relación puede adquirir un papel fuerte o débil.
Conjunto de entidades débiles
Es aquel conjunto de entidades que no tiene atributos que puedan identificar una entidad en forma única, o sea que no poseen atributos para conformar la llave primaria; por lo tanto dependen de una entidad fuerte.
Conjunto de entidades fuertes
Conjunto de entidades que posee una clave primaria.
Discriminante en entidades débiles
El discriminante de un conjunto de entidades débiles es un conjunto de atributos que permite que se haga esta distinción.
Ejemplo
Considérese el conjunto de entidades pago, que tiene tres atributos: numero_pago, fecha_pago e importe_pago. Los números de pago suelen ser números secuenciales, a partir de 1, generados independientemente para cada préstamo. Por tanto, aunque cada entidad pago es distinta, los pagos de diferentes préstamos pueden compartir el mismo número de pago. Así, este conjunto de entidades no tiene clave primaria; es un conjunto de entidades débiles. Como el numero_pago es único para cada págo, a este conjunto de atributos le llamaremos discriminante.
Aunque los conceptos básicos del modelo E-R pueden moldear la mayor parte de las características de las bases de datos, algunos aspectos de las bases de datos se pueden expresar mejor mediante ciertas extensiones del modelo E-R básico. En este apartado se estudian las características E-R extendidas de:
INDICACIONES: El examen se presenta el día viernes 18 de enero de 2019.
Elabora los siguientes diagramas E-R en tu cuaderno, fecha limite de entrega jueves 17 de enero de 2019:
Sistema para almacenar, organizar y controlar información ofreciendo seguridad y un fácil acceso a la misma, haciendo eficiente la manipulación de datos. Conjunto estructurado de datos que representam entidades y sus interrelaciones.
Ayudar a la gente y a las organizaciones a llevar un registro de las cosas, de aquellos objetos acerca de los cuales les interesa guardar datos. Estos datos son los que permitirán generar información de esas cosas u objetos. Para comprender por qué es importante este almacenamiento de datos, se puede primero analizar qué problemas se presentan cuando se utilizan sólo datos, sin la estructura que ofrece una Base de Datos:
Ventajas
Un sistema de base de datos sirve para integrar los datos. Sus componentes se dividen:
Las bases de datos como su nombre lo indica se componen de datos y metadatos los cuales definen la estructura de la misma. La visión general de las BD la subdivide en dos estructuras:
Software que permite al usuario procesar, describir, administrar y recuperar los datos almacenados en una BD.

El éxito del DBMS reside en mantener la seguridad e integridad de los datos. Logicamente proporciona las herramientas a los distintos usuarios, dichas herramientas son:
Específico en cada SGBD. Para la definición y la modificación de esquemas externos (CREATE VIEW), conceptuales (CREATE TABLE), y estructuras internas (CREATE INDEX). Permiten describir restricciones de integridad (CREATE ASSERTION), los utiliza fundamentalmente el administrador de la BD, los diferentes esquemas (al ser compilados), dan lugar a diccionarios (orientado al usuario) y directorios de datos (orientado al sistema).
Funciona sobre los esquemas de las BD definidos con el LDD. Incluye sentencias para añadir (INSERT), eliminar (DELETE), actualizar (UPDATE), así como para buscar (SELECT) información de la BD.
Para tareas especificas de organización y gestión de la BD (asignar privilegios, prioridades, etc.)
El diseño de una base de datos consiste en definir la estructura de los datos que debe tener un sistema de información determinado.
La siguiente información es tomada del libro FUNDAMENTOS DE BASES DE DATOS de Abraham Silberschatz, Henry F. Korth, S. Sudarshan, Cuatra Edición. La estructura lógica general de una base de datos se puede expresar gráficamente mediante un diagrama E-R. Los diagramas son simples y claros, cualidades que pueden ser responsables del amplio uso del modelo E-R. Tal diagrama consta de los siguientes componentes principales:
Las relaciones ilustran una asociación entre dos tablas. En el modelo de datos físicos, las relaciones están representadas por líneas estilizadas Cardinalidad y ordinalidad, respectivamente, se refiere al máximo número de veces que una instancia en una entidad puede ser asociada con instancias en la entidad relacionada, y el mínimo número de veces que una instancia en una entidad puede ser asociada con instancias en la entidad relacionada. Cardinalidad y ordinalidad están representadas por el estilo de una línea y su punto final, como se indica en el estilo de notación elegido. Fuente: (https://www.lucidchart.com/pages/es/s%C3%ADmbolos-y-significado-de-diagramas-ER)
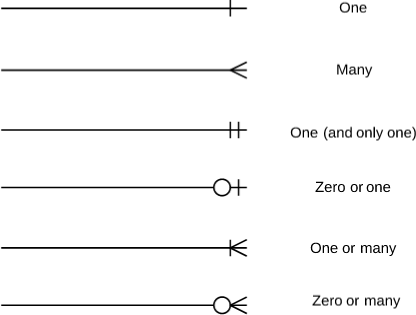
Para más información consulte: https://www.ibm.com/support/knowledgecenter/es/SSEP7J_10.2.2/com.ibm.swg.ba.cognos.ug_cog_rlp.10.2.2.doc/c_cog_rlp_rel_cardinality.html
En el modelo relacional de las dos capas de diseño conceptual y lógico, se parecen mucho. Generalmente se implementan mediante diagramas de Entidad/Relación (modelo conceptual) y tablas y relaciones entre éstas (modelo lógico). Este es el modelo utilizado por los sistemas gestores de datos más habituales (SQL Server, Oracle, MySQL, etc.)
El modelo relacional de base de datos se rige por algunas normas sencillas:
Una vez claro el modelo E-R debemos traducirlo a un modelo lógico directamente en el propio gestor de base de datos (Oracle, MySQL, SQL Server, etc). Si hemos utilizado alguna herramienta profesional para crear el diagrama E-R, seguramente podremos generar automáticamente las instrucciones necesarias para crear la base de datos.
Como hemos viisto, las instrucciones DML (Data Manipulation Languauge - Lenguaje de Manipulación de Datos) trabajan sobre los datos almacenados en nuestro SGBD, permitiendo consultarlos o modificarlos.
En general a las operaciones básicas de manipulación de datos que podemos realizar con SQL se les denomina operaciones CRUD (de Create, Read, Update and Delete, osea, Crear, Leer, Actualizar y Borrar, Sería CLAB en español, pero no se usa).
Hay cuatro instrucciones para realizar estas tareas:
Es un lenguaje utilizado por la mayoría de los SGBDR surgidos a fines de los años 70, y que llega hasta nuestros días.
En 1986 fue estandarizado por el organismo ANSI (American Nacional Standard Institute), dando lugar a la primera versión estándar de este lenguaje, el SQL-86 o SQL1. Al año siguiente este estándar es adoptado también por el organismo internacional ISO (International Standarization Organization).
A lo largo del tiempo se ha ido ampliando y mejorando. En la actualidad SQL es el estándar de facto de la inmersa mayoría de los SGBDR comerciales. El soprte es general y muy amplio, pero cada sistema (Oracle, SQL Server, MySQL, etc.) incluye sus ampliaciones y pequeñas particularidades.
El ANSI SQL ha ido sufrido varias revisiones a lo largo del tiempo.
 Creación de una base de datos relacional
Creación de una base de datos relacional
CREATE SCHEMA {[nombre_esquema] | [AUTHORIZATION usuario]} [lista_de_elementos_del_esquema];
borrado de una base de datos relacional
DROP SCHEMA nombre_esquema {RESTRICT|CASCADE};
Creación de una tabla
CREATE TABLE [ {GLOBAL | LOCAL} TEMPORARY ] < nombre de la tabla >
( < elemento de la tabla > [ { , < elemento de la tabla > } ... ] )
[ON COMMIT {PRESERVE | DELETE } ROWS ]
CREATE TABLE DISCOS_COMPACTOS
( ID_DISCO_COMPACTO INT,
TITULO_CD VARCHAR(60),
ID_DISQUERA INT
);
Modificación de una tabla
ALTER TABLE < nombre de la tabla >
ADD [COLUMN] < definición de columna >
| ALTER [COLUMN] < nombre de columna >
{ SET DEFAULT < valor predeterminado > | DROP DEFAULT }
| DROP [COLUMN] < nombre columna > { CASCADE | RESTRICT }
ALTER TABLE ARTISTAS
ADD COLUMN FDN_ARTISTA DATE;
ALTER TABLE ARTISTAS
ALTER COLUMN LUGAR_DE_NACIMIENTO SET DEFAULT 'Desconocido';
ALTER TABLE ARTISTAS
ALTER COLUMN LUGAR_DE_NACIMIENTO DROP DEFAULT;
ALTER TABLE ARTISTAS
DROP COLUMN LUGAR_DE_NACIMIENTO CASCADE;
Eliminación de una tabla
DROP TABLE < nombre de la tabla > { CASCADE | RESTRICT }
DROP TABLE ARTISTAS CASCADE;
Para cada columna tenemos que elegir entre algún dominio definido por el usuario o alguno de los tipos de datos predefinidos que se describen a continuación:
|
|
|
|---|---|
| Tipos de datos | Descripción |
| CHARACTER (longitud) | Cadenas de caracteres de longitud fija |
| CHARACTER VARYING | Cadenas de caracteres de longitud variable |
| BIT (longitud) | Cadenas de bits de longitud fija |
| BIT VARYING | Cadenas de bits de longitud variables |
| NUMERIC (precisión, escala) | Números decimales con tantos dígitos como indique la presición y tantos decimales como indique la escala |
| DECIMAL (precisión, escala) | Número decimales con tantos dígitos como indique la presición y tantos decimales como indique la escala |
| INTEGER | Números ennteros |
| SMALLINT | Números enteros pequeños |
| REAL | Números con coma flotante con prescisión predefinida |
| FLOAT (precisión) | Números con coma flotante con la precisión especificada |
| DOUBLE PRECISIÓN | Números con coma flotante con más precisión predefinida que la del tipo REAL |
| DATE | Fechas. Están computestas de: YEAR, MONTH, DAY |
| TIME | Horas. Están compuestas de HOUR, MINUT, SECOND |
| TIMESTAMP | Fechas y horas. Están compuestas de YEAR, MONTH, DAY, HOUR, MINUT, SECOND |
Tipos definidos por el usuario
CREATE TYPE < nombre del tipo > AS < tipo de atributo > FINAL; CREATE TYPE SALARIO AS NUMERIC(8,2) FINAL; CREATE TABLE EMPLEADO ( ID_EMPLEADO INTEGER, SALARIO_EMPLEADO SALARIO );
Valores predeterminados en una columna
< nombre de columna > < tipo de datos > DEFAULT < valor predeterminado > CREATE TABLE ARTISTAS ( ID_ARTISTA INT, NOMBRE_ARTISTA VARCHAR(60), LUGAR_DE_NACIMIENTO VARCHAR(60) DEFAULT 'Desconocido' );
 NOT NULL
NOT NULL
CREATE TABLE ARTISTAS_DISCO_COMPACTO ( ID_ARTISTA INT NOT NULL, NOMBRE_ARTISTA VARCHAR(60) NOT NULL, LUGAR_DE_NACIMIENTO VARCHAR(60) );
UNIQUE
CREATE TABLE CD_INVENTARIO ( NOMBRE_ARTISTA VARCHAR(40), NOMBRE_CD VARCHAR(60) UNIQUE, DERECHOSDEAUTOR INT ) CREATE TABLE CD_INVENTARIO ( NOMBRE_ARTISTA VARCHAR(40), NOMBRE_CD VARCHAR(60), DERECHOSDEAUTOR INT, CONSTRAINT UN_ARTISTA_CD UNIQUE (NOMRE_ARTISTA, NOMBRE_CD) ); CREATE TABLE CD_INVENTARIO ( NOMBRE_ARTISTA VARCHAR(40), NOMBRE_CD VARCHAR(60) NOT NULL UNIQUE, DERECHOSDEAUTOR INT ); CREATE TABLE CD_INVENTARIO ( NOMBRE_ARTISTA VARCHAR(40), NOMBRE_CD VARCHAR(60) NOT NULL, DERECHOSDEAUTOR INT, CONSTRAINT UN_ARTISTA_CD UNIQUE (NOMBRE_CD) );
Restricciones PRIMARY KEY
CREATE TABLE CD_ARTISTAS ( ID_ARTISTA INT PRIMARY KEY, NOMBRE_ARTISTA VARCHAR(60), ID_ANGENCIA INT ); CREATE TABLE CD_ARTISTAS ( ID_ARTISTA INT, NOMBRE_ARTISTA VARCHAR(60), ID_AGENCIA INT, CONSTRAINT PK_ID_ARTISTA PRIMARY KEY (ID_ARTISTA, NOMBRE_ARTISTA) ); CREATE TABLE CD_ARTISTAS ( ID_ARTISTA INT PRIMARY KEY, NOMBRE_ARTISTA VARCHAR(60), ID_AGENCIA INT, CONSTRAINT UN_NOMBRE_ARTISTA UNIQUE (NOMBRE_ARTISTA) ); CREATE TABLE CD_ARTISTAS ( ID_ARTISTA INT, NOMBRE_ARTISTA VARCHAR(60) UNIQUE, ID_AGENCIA INT, CONSTRAINT PK_ID_ARTISTA PRIMARY KEY (ID_ARTISTA) );
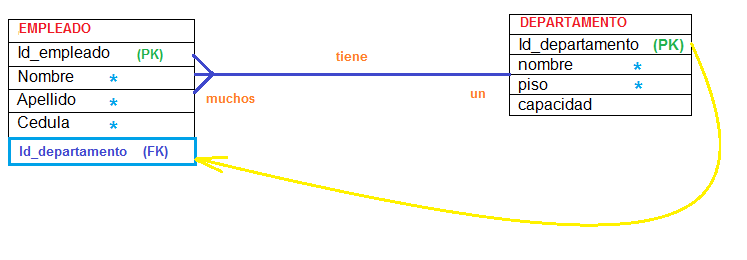
Restricciones FOREIGN KEY
CREATE TABLE TITULOS_CD ( ID_TITULO_CD INT, TITULO_CD VARCHAR(60), ID_EDITOR INT REFERENCES EDITORES_CD ); CREATE TABLE TITULOS_CD ( ID_TITULO_CD INT, TITULO_CD VARCHAR(60), ID_EDITOR INT, CONSTRAINT FK_ID_EDITOR FOREING KEY (ID_EDITOR) REFERENCES EDITORES_CD (ID_EDITOR) );
Restricciones CHECK
CREATE TABLE TITULOS_CD
( ID_DISCO_COMPACTO INT,
TITULO_CD VARCHAR(60) NOT NULL,
EN_EXISTENCIA INT NOT NULL,
CONSTRAINT CK_EN_EXISTENCIA CHECK (EN_EXISTENCIA > 0 AND EN_EXISTENCIA < 30)
);
CREATE TABLE TITULOS_CD
( ID_DISCO_COMPACTO INT,
TITULO_CD VARCHAR(60) NOT NULL,
EN_EXISTENCIA INT NOT NULL
CHECK (EN_EXISTENCIA > 0 AND EN_EXISTENCIA < 30)>)
);
CREATE TABLE TITULOS_CD
( ID_DISCO_COMPACTO INT,
TITULO_CD VARCHAR(60) NOT NULL,
ERA CHAR(5),
CONSTRAINT CK_ERA CHECK (ERA IN ('1940s','1950s','1960s','1970s','1980s','1990s','2000s'))
);
CREATE TABLE TITULOS_CD
(
ID_DISCO_COMPACTO INT,
TITULO_CD VARCHAR(60) NOT NULL,
ERA CHAR(5),
CONSTRAINT CK_ERA CHECK
(
ERA IN
(
'1980s','1990s','2000s'
)
)
);
CREATE TABLE TITULOS_CD
( ID_DISCO_COMPACTO INT,
TITULO_CD VARCHAR(60) NOT NULL,
EN_EXISTENCIA INT NOT NULL,
CONSTRAINT CK_EN_EXISTENCIA CHECK
(
(EN_EXISTENCIA BETWEEN 0 AND 30)
OR
(EN_EXISTENCIA BETWEEN 49 AND 60)
)
);
INDICACIONES: Elabora un Modelo Entidad Relación utilizando el Workbench de MySQL. Fecha: viernes 9 de febrero de 2018.
Da clic aquí para descargar las indicaciones.Las restricciones se utilizan para especificar reglas para los datos en un tabla. Se pueden especificar cuando la tabla se crea con la instrucción CREATE TABLE, o después de que la tabla se crea con la sentencia ALTER TABLE. Las restricciones son:
CREATE TABLE personas ( ID int NOT NULL, nombre varchar(255) NOT NULL, apellido_p varchar(255) NOT NULL, apellido_m varchar(255) NOT NULL, edad int );
CREATE TABLE personas ( ID int NOT NULL UNIQUE, nombre varchar(255) NOT NULL, apellido_p varchar(255) NOT NULL, apellido_m varchar(255) NOT NULL, correo varchar(255) NOT NULL, edad int, UNIQUE(correo, ID) ); //Agregar un campo único ALTER TABLE personas ADD UNIQUE(correo); ALTER TABLE personas ADD CONSTRAINT C_Personas UNIQUE(ID,correo); //Eliminar restricción única ALTER TABLE personas DROP INDEX C_Personas;
CREATE TABLE personas ( ID int NOT NULL, nombre varchar(255) NOT NULL, apellido varchar(255), edad int, PRIMARY KEY (ID) ); CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT PK_Person PRIMARY KEY (ID) ); //Para modificar PRIMARY KEY ALTER TABLE personas ADD PRIMARY KEY (ID); ALTER TABLE personas ADD CONSTRAINT PK_Persona PRIMARY KEY (ID); //Para borrar PRIMARY KEY ALTER TABLE personas DROP PRIMARY KEY; ALTER TABLE personas DROP CONSTRAINT PK_Person;
CREATE TABLE ordenes ( id_orden int NOT NULL, numero_orden int NOT NULL, id_persona int, PRIMARY KEY (id_orden), FOREIGN KEY (id_persona) REFERENCES personas(ID) ); CREATE TABLE ordenes ( id_orden int NOT NULL, numero_orden int NOT NULL, id_persona int, PRIMARY KEY (id_orden), CONSTRAINT FK_PersonaO FOREIGN KEY (id_persona) REFERENCES personas(ID) ); //Modificar FOREIGN KEY ALTER TABLE ordenes ADD FOREIGN KEY (id_persona) REFERENCES personas(id_personas); ALTER TABLE ordenes ADD CONSTRAINT FK_PersonaOrden FOREIGN KEY (id_persona) REFERENCES personas(ID); //Borrar FOREIGN KEY ALTER TABLE ordenes DROP FOREIGN KEY FK_PersonsOrden;
La restricción CHECK se utiliza para limitar el rango de valores que se puede colocar en una columna. Si define una restricción CHECK en una sola columna, solo permite ciertos valores para esta columna. Si define una restricción CHECK en una tabla, puede limitar los valores en ciertas columnas en función de los valores en otras columnas de la fila.
CREATE TABLE personas ( ID int NOT NULL, nombre varchar(255) NOT NULL, apellido_p varchar(255), edad int, CHECK (edad>=18) ); CREATE TABLE personas ( ID int NOT NULL, nombre varchar(255) NOT NULL, apellido_p varchar(255), edad int, ciudad varchar(255), CONSTRAINT CHK_Persona CHECK (edad>=18 AND ciudad='Gómez Palacio') ); //Modificar un CHECK ALTER TABLE personas ADD CHECK (edad>=18); ALTER TABLE personas ADD CONSTRAINT CHK_PersonaEdad CHECK (edad>=18 AND ciudad='Lerdo'); //Borrar un CHECK ALTER TABLE personas DROP CHECK CHK_PersonaEdad;
CREATE TABLE personas ( ID int NOT NULL, nombre varchar(255) NOT NULL, apellido_p varchar(255), edad int, ciudad varchar(255) DEFAULT 'Sandnes' ); CREATE TABLE Orders ( ID int NOT NULL, numero int NOT NULL, fecha date DEFAULT GETDATE() ); //Modificar DEFAULT ALTER TABLE personas ALTER ciudad SET DEFAULT 'Sandnes'; //Borrar DEFAULT
Los índices se utilizan para recuperar datos de la base de datos muy rápido. Los usuarios no pueden ver los índices, solo se utilizan para acelerar las búsquedad/consultas.
CREATE INDEX idx_apellido ON personas (apellido_p); CREATE INDEX idx_nombre ON personas (apellido_p, apellido_m); //Aquí los valores duplicados no son permitidos CREATE UNIQUE INDEX idx_nombre ON personas (nombre, apellido_p, apellido_m); //Para borrar un indice ALTER TABLE personas DROP INDEX idx_nombre;
El incremento automático permite que se genere automáticamente un número único cuando se inserta un nuevo registro en una tabla. A menudo, este es el campo clave principal que nos gustaría que se cree automáticamente cada vez que se inserta un nuevo registro.
CREATE TABLE personas (
ID int NOT NULL AUTO_INCREMENT,
nombre varchar(255) NOT NULL,
apellido_p varchar(255),
edad int,
PRIMARY KEY (ID)
);
//Modificar un auto_increment para que comience
//En un valor predeterminado en este caso 50
ALTER TABLE personas AUTO_INCREMENT = 50;
//Inserción sin contemplar el campo con el A_I
INSERT INTO personas (nombre, apellido_p)
VALUES ('Aarón','Salazar');
Elabora el código en MySQL de las siguientes prácticas: Práctica1: Se solicita una base de datos Un para el registro de las distribuciones de paquetes por camioneros.
MySQL viene con los siguientes tipos de datos para almacenar una fecha o un valor de fecha/hora en la base de datos:
En SQL, una VIEW es una tabla virtual basada en el conjunto de resultados de una declaración de MySQL. Una vista contiene filas y columnas, al igual que una tabla real. Los campos en una vista son campos de una o más tablas reales en la base de datos. Puede agregar funciones de MySQL, WHERE y JOIN a una vista y presentar los datos como si los datos provinieran de una sola tabla.
CREATE VIEW vista_personas AS SELECT * FROM personas; CREATE VIEW vista_personas_prestamos AS SELECT * FROM personas INNER JOIN prestamos ON personas.id_personas = prestamos.id_prestamos; CREATE VIEW vista_personas AS SELECT * FROM personas WHERE edad > 17; //Para acceder a la vista: SELECT * FROM vista_personas;
Da clic aquí para conocer más sobre las funciones incorporadas en MySQL
Estas funciones se pueden clasificar grupos de:
Práctica1: Elabora una serie de consultas para conocer más sobre las funciones incorporadas en MySQL:
En las siguientes ligas encontrarás información sobre lo que son los metamodelos en bases de datos.
Elabora una presentación (máximo 10 diapositivas) acerca de los metamodelos y súbela a la carpeta de box en una carpeta llamada unidad3. Fecha limite de subida: Miércoles 14 de febrero de 2018.
Definición de Metamodelo
Modelos y Metamodelos
Resuleve un cuestionario de conocimiento utilizando como guía de estudio los temas 1, 2 y 3 de la Unidad 2 y tema 1 de la Unidad 3. Fecha: lunes 12 de febrero de 2018.
La siguiente información es tomada del libro "La biblia de MySQL", IAN Gilfillan, Anaya Multimedia
Existen dos tipos de tablas de transacción segura (InnoBD y BDB). El resto (ISAM, MyISAM, MERGE y HEAP) no son de transacción segura. La elección de tipo de tabla adecuado puede afctar eenormemente al rendimiento.
Las tablas del tipo Método de acceso secuencial indexado (ISAM) era eel estándar antiguo de MySQL. Estas fueron sustituidas por las tablas MyISAM en la versión 2.23.0 (aunque los tipos ISAM seguiran estando disponibles hasta MySQL 4.1). Por lo tanto, es probable que sólo se tope con este tipo de tablas si esta trabajando con bases de datos antiguas. La principal diferencia entre los dos es que el índice de las tablas MyISAM es mucho mas pequeño que el de las tablas ISAM, de manera que una instrucción SELECT con un índice sobre una tabla MyISAM utilizara muchos menos recursos del sistema. En contrapartida, las tablas de tipo MyISAM necesitan mucha mas potencia de procesador para insertar un registro dentro de un índice mas comprimido. Las tablas ISAM presentan las siguientes características:
ALTER TABLE nombre_de_la_tabla ENGINE = MYISAM;
Las tablas de tipo ISAM sustituyeron a las tablas ISAM en la versión 3.23.0. Los indices MyISAM son mucho más pequeños que los indices ISAM. Deibido a ello, el sistema utiliza menos recursos al realizar una operación de selección mediante un índice de una tabla MyISAM. Sin embargo, MyISAM requiere mas potencia de procesador para insertar un registro dentro de un índice mucho mas comprimido.
Los archivos de datos MyISAM llevan asignada la extensión .MYD y la extensión de los indices .MYI. Las bases de datos MyISAM se almacenan en un directorio.
Existen tres subtipos de tablas MyISAM: estáticas, dinámicas y comprimidas. Al crear las tablas, MySQL escoge entre el tipo dinámico o el tipo estático. El tipo predeterminado son las tablas estáticas y se crean si no incluyen columnas tipo VARCHAR, BLOB o TEXT. De lo contrario, la tabla se convierte en tabla dinámica.
Las tablas MERGE son la fusiónd e tablas MyISAM iguales. Este tipo de tablas se introdujeron en la versión 3.23.25. Por regla general sólo se utilizan cuando las tablas MyISAM empiezan a resultar demasiado grandes. Entre las ventajas de estas tablas se puede mencionar las siguientes:
CREATE TABLE sales_rep1 ( id INT AUTO_INCREMENT PRIMARY KEY, employee_number INT(11), surname VARCHAR(40), frist_name VARCHAR(30), commission TINYINT(4), date_joined DATE, birthday DATE ) ENGINE=MyISAM;
CREATE TABLE sales_rep2 ( id INT AUTO_INCREMENT PRIMARY KEY, employee_number INT(11), surname VARCHAR(40), frist_name VARCHAR(30), commission TINYINT(4), date_joined DATE, birthday DATE ) ENGINE=MyISAM;
CREATE TABLE sales_repl_2 ( id INT AUTO_INCREMENT PRIMARY KEY, employee_number INT(11), surname VARCHAR(40), frist_name VARCHAR(30), commission TINYINT(4), date_joined DATE, birthday DATE ) ENGINE=MERGE UNION=(sales_rep1,sales_rep2);A continuación, insertaremos algunos datos dentro de las tablas para poder probarlas:
INSERT INTO sales_rep1 VALUES (1,'Tshwete','Paul',15,'1999-01-03','1970-03-04'); INSERT INTO sales_rep2 VALUES (2,'Grobler','Peggy-Sue',12,'2001-11-19','1956-08-25');Ahora, si realizamos una consulta sobre la tabla cominada, todos los registros de sales_repl y sales_rep2 estarán disponibles:
SELECT first_name,surname FROM sales_repl_2;En función a los resultados anteriores, no es posible saber de que tabla subyacente proceden. Afortunamdamente, no necesitaremos saberlo si estamos actualizando un registro. La siguiente instrucción:
UPDATE sales_repl_2 SET first_name = 'Peggy' WHERE first_name = 'Peggy-Sue';Actualizará el registro correctamente. Como el registro sólo existe fisicamente en el nivel subyacente reflejaran los datos correctamente, como se demuestra a continuación:
SELECT first_name,surname FROM sales_repl_2; SELECT first_name,surname FROM sales-rep2;Lo mismo se aplica a las instrucciones DELETE:
DELETE FROM sales_rep1_2 WHERE first_name = 'Peggy';El registro se elimina en el nivel subyacente, por lo que desaparecera de las consulta en la tabla MERGE y en la tabla subyacente:
SELECT first_name, surname FROM sales_repl_2; SELECT first_name,surbame FROM sales-rep2;Sin embargo si se intenta realizar una operación de inserción MySQL no sabrá en que tabla subyacente insertar el registro y devolvera error:
INSERT INTO sales_repl_2 VALUES ('Shephard','Earl',11,'2002-12-15','1961-05-31');
Por suerte existe una solución, que fue introducida en la versión 4 (antes no se podían insertar registros en las tablas MERGE). Al crear una tabla MERGE, podemos especificar en que tabla realizar las inserciones. Fijese en la última cláusula de la siguiente instrucción CREATE:
CREATE TABLE sales_repl_2 ( id INT AUTO-INCREMENT PRIMARY KEY, employee_number INT(11), surname VARCHAR(40), first_name VARCHAR(30), commission TINYINT(4), date_joined DATE, birthday DATE ) ENGINE=MERGE UNION=(sañes_rep1,sales_rep2) INSERT_METHOD = LAST;INSERT_METHOD puede ser NO, FIRST o LAST. A continuación, los registros insertados se colocan dentro de la primera tabla en la lista de unión, en la última tabla o en ninguna. El valor predeterminado es NO.
Las tablas HEAP son el tipo de tabla más rápido porque se almacenan en memoria y utilizan un índice asignado. La contrapartida es que, como se almaceman en memoria, todos los datos se pierden en caso de un fallo en el sistema. Además, no pueden contener una gran cantidad de datos (a menos que disponga de un gran presuppuesto para RAM). Como en el caso de cualquier otra tabla, puede crear una en función de los contenidos de otra. Las tablas HEAP se suelen utilizar para acceder rápidamente a una tabla ya existente (se deja la tabla original para labores de inserción y de actualización, y la nueva tabla se utiliza para realizar lecturas rápidas). A continuación, crearemos una tabla a partir de la tabla sales_rep.
CREATE TABLE sales_rep ( employee_number INT(11) DEFAULT NULL, surname varchar(40) DEFAULT NULL, first_name VARCHAR(30) DEFAULT NULL, commission TINYINT(40) DEFAULT NULL, date_joined DATE DEFAULT NULL, birthday DATE DEFAULT NULL ) ENGINE=MyISAM; INSERT INTO sales-rep VALUES (1,'Rive','Sol',10,'2000-02-15','1976-03-18'); INSERT INTO sales-rep VALUES (2,'Gordimer','Charlene',15,'1998-07-09','1958-11-30'); INSERT INTO sales-rep VALUES (3,'Serote','Mike',10,'2001-05-14','1971-06-18'); INSERT INTO sales-rep VALUES (4,'Rive','Mongane',10,'2002-11-23','1982-01-04');Ahora crearemos una tabla HEAP que tome un subconjunto de elementos de sales-rep y los coloque en memoria para brindar un acceso más rápido:
CREATE TABLE heaptest ENGINE=HEAP SELECT first_name,surname FROM sales_rep; SELECT * FROM heaptest;
Las tablas InnoDB son tablas de transacción segura (lo que significa que disponen de las funciónes COMMIT y ROLLBACK). En una tabla MyISAM, la tabla entera se bloquea al realizar funciones de inserción. durante esa fracción de segundo, no se puede ejecutar ninguna de otra instrucción sobre la tabla. InnoDB utiliza funciones de bloqueo en el nivel de fila de manera que solo se bloquee dicha fila y no toda la tabla, y se puedan seguir aplicando instrucciones sobre otras filas.
Por razones de rendimiento, es aconsejable utilizar tablas InnoDB s necesita realizar una gran cantidad de operaciones de inserción y actualización sobre los datos de sus tablas en comparación con operaciones de selección. Por el contrario, si las operaciones de selecion superan a las de actualización o inserción, es preferible inclinarse por las tablas MyISAM.
Para utilizar tablas InnoDB, es necesario compilar MySQL con compatibilidad InnoDB.
CREATE TABLE innotest ( f1 INT, f2 CHAR(10), INDEX(f1) ) ENGINE=InnoDB;
DBD equivale a Bases de Datos de Berkeley (creada originalmente en la University of California, Berkeley). Se trata también de un tipo de tabla habilitada para transacciones. Como en el caso de las tablas InnoDB, es necesario compilar la compatibilidad de BDB en MySQL para que funcione (la distribución mysql-max incorpora dicha función).
Para crear una table BDB, basta con utilizar TYPE=BDB tras la instrucción CREATE TABLE:
CREATE TABLE bdbtest ( f1 INT, f2 CHAR(10) ) ENGINE=BDB;
Práctica1: Elabora una base de datos para registrar y mostrar los alumnos de las diferentes facultades de la UJESD.
Los operadores de comparación se utilizan para realizar comparaciones entre valores. Por ejemplo, podemos afirmar que 34 es mayor que 2. La expresión es mayor que es un operador de comparación. A continuación se describen los operadores de comparación en MySQL:
| Operador | Sintaxis | Descripción |
|---|---|---|
| = | a=b | Verdad si a y b son iguales (Excluyendo NULL) |
| !=,< > | a!=b, a< > b | Verdas si a no es igual a b |
| > | a>b | Verdad si a no es igual a b |
| < | a < b | Verdad si a es menor que b |
| >= | a>=b | a es mayor igual a b |
| <= | a<=b | a es menor igual a b |
| < = > | a< = >b | Verdad si a es menor igual que b |
| IS NULL | a IS NULL | Verdas si a contiene un valor NULL |
| IS NOT NULL | a IS NOT NULL | Verdad si a no contiene un valor NULL |
| BETWEEN | a BETWEEN b AND c | Verdad si a esta entre los valores de b y c, amos inclusive |
| NOT BETWEEN | a NOT BETWEEN b AND c | Verdad si a no esta entre los valores de b y c, ambos inclusive |
| LIKE | a LIKE b | Verdad si a equivale a b en una correspondencia de patrón SQL |
| NOT LIKE | a NOT LIKE b | Verdas si a no equivale con b en una correspondencia de patrón SQL. |
| IN | a IN (b1,b2,b3) | Verdad si a es igual a algún elemento de la lista |
| NOT IN | a NOT IN (b1,b2,b3) | Verdad si a no es igual a algún elemento de la lista |
| REGEXP, RLIKE | a REGEXP b, a RLIKE b | Verdad si a equivale a b con una expresión regular |
| NOT REGEXP, NOT RLIKE | a NOT REGEXP b, a NOT RLIKE b | Verdas si a no equivale a b con una expresión regular (Link de expresiones regulares) |
Práctica1: Elabora una base de datos para registrar los artículos escritos por algunos autores pertenecientes a alguna instituación educativa.
CREATE TABLE customer ( id INT(11) DEFAULT NULL; surname VARCHAR(40) DEFAULT NULL ) TYPE=MyISAM; INSERT INTO customer VALUES (1,'Yvonne','Clegg'); INSERT INTO customer VALUES (2,'Johnny','Chaka-Chaka'); INSERT INTO customer VALUES (3,'Winston','Powers'); INSERT INTO customer VALUES (4,'Patricia','Mankunku'); CREATE TABLE sales ( code INT(11) DEFAULT NULL, sales_rep INT(11) DEFAULT NULL, customer INT(11) DEFAULT NULL, value INT(11) DEFAULT NULL ) TYPE=MyISAM; INSERT INTO sales VALUES (1,1,1,2000); INSERT INTO sales VALUES (2,4,3,250); INSERT INTO sales VALUES (3,2,3,500); INSERT INTO sales VALUES (4,1,4,450); INSERT INTO sales VALUES (5,3,1,3800); INSERT INTO sales VALUES (6,1,2,500); CREATE TABLE sales-rep ( employee_number INT(11) DEFAULT NULL, surname VARCHAR(40) DEFAULT NULL, first_name VARCHAR(30) DEFAULT NULL, commmission TINYINT(4) DEFAULT NULL, date_joined DATE DEFAULT NULL, birthday DATE DEFAULT NULL ) TYPE=MyISAM; INSERT INTO sales_rep VALUES (1,'Rive','Sol',10,'2000-02-15','1976-03-18'); INSERT INTO sales_rep VALUES (2,'Gordimer','Charlene',15,'1998-07-09','1971-06-18'); INSERT INTO sales_rep VALUES (3,'Serote','Mike',10,'2001-05-14','1971-06-18'); INSERT INTO sales_rep VALUES (4,'Rive','Mongane',10,'2002-11-23','1982-01-04');Ahora comencemos por una combinación básica:
SELECT sales_rep, customer, value, first_name, surname FROM sales, sales_rep WHERE code=1 AND sales_rep.employee_number=sales.sales_rep;Como la relación entre las tablas sales_rep y sales se establece a partir de employee_number o sales_rep, estos dos campos forman la condición de combinación de la cláusula WHERE.
SELECT sales_rep.first_name, sales_rep.surname, value, customer.first_name, customer.surname FROM sales, sales_rep, customer WHERE sales_rep.employee_number = sales.sales_rep AND customer.id = sales.customer;El campo employee_number de la tabla sales_rep esta relacionado con el campo sales_rep de la tabla sales. Y el campo id de la tabla customer está relacionado con el campo customer de la tabla sales. No existen otras condiciones, por lo que esta consulta devuelve todas las ventas para las que existen filas correspondientes en la tabla sales_rep y en la tabla customer.
Las combinaciones internas son otra forma de describir el primer tipo de combinación aprendido. Las siguientes dos consultas son identicas:
SELECT first_name,surname,value FROM customer, sales WHERE id=customer; SELECT first_name, surname, value FROM customer INNER JOIN sales ON id=customer;
Imagine que hemos hecho otra ventana, con la diferencia de que esta vez el pago se ha realizado al contado y el cliente se ha marchado con los artículos sin que le hayamos tomado los datos. No hay problema porque todavía podemos agregarlos a la tabla sales utilizando un valor null para el cliente.
INSERT INTO sales VALUES (7, 2, NULL, 670);Vamos a ejecutar de nuevo la consulta que devuelve el valor y los nombre de los comerciales y clientes para cada venta:
SELECT sales_rep.first_name, sales_rep.surname, value, customer.first_name, customer.surname FROM sales, sales_rep, customer WHERE sales_rep.employee_number = sales.sales_rep AND customer.id = sales.customer;En la consulta anterior no arroja el cliente con el valor NULL en la tabla sales, la condición de combinación no se cumple. Como recordará, el operador = excluye a los vlores NULL. El operador < = > no nos sirvirá de ayuda porque la tabla customer no incluye registros NULL, de manera que no serviría una igualdad que admita valores núlos. La solución en este caso consiste en realizar una combinación externa. Esta combinación devolvera un resultado para cada registro coincidente de una tabla, independientemente de que exista un registro asociado en la otra tabla. Por lo tanto, aaunque el campo customer sea NULL en la tabla sales y no exista relación con la tabla customer sea NULL en la tabla sales y no exista relación con la tabla customer, se devolvera un registro. Una combinación externa por la izquierda devuelve todas las filas coincidentes de la tabla izquerda, independientemente de si existe una fila correspondiente en la tabla de la derecha. La sintaxis de las combinaciones externas por la izquierda es la siguiente:
SELECT campo1, campo2 FROM tabla1 LEFT JOIN tabla2 ON campo1=campo2En primer lugar vamos a probar con un ejemplo sencillo que realiza una combinación por la izquierda sobre las tablas customer y sales.
SELECT first_name, surname, value FROM sales LEFT JOIN customer ON id=customer;El orden de la tabla es importante en una combinación por la izquierda. La tabla desde la que se devuelven todas las filas coincidentes debe ser la tabla de la izquierda (antes de las palabras clave LEFT JOIN). Si invertimos el oden e intentamos lo siguiente:
SELECT first_name, surname, value FROM customer LEFT JOIN sales ON id=customer;Obtenemos otro resultado. Como la tabla izquierda es la tabla de clientes en esta consulta y la operación de combinación solo busca coincidencias en los registros de la tabla izquierda, no se devuelve el registro de ventas con el cliente NULL (lo que significa que no hayr elación con la tabla customer).
Las combinacinoes por la derecha son exactamente iguales a las combinaciones por la izquierda, con la salvedad de que en el orden de la combinación se invierte. Para recuperar el nombre de todos los clientes para cada venta, incluyendo aquellas de las que no se dispongan de datos de los clientes, debemos colocar la tabla sales en la parte derecha de la combinación.
SELECT first_name, surname, value FROM customer RIGHT JOIN sales ON id=customer;NOTA: Si duda en cuanto al lado en el cual colocar la tabla, recuerde que una combinación por la derecha lee todos los registros de la tabla derecha, incluyendo los nulos, y una combinación por la izquierda lee todos los registros por la izquierda desde la tabla izquierda, incluyendo los nulos.
Estas combinaciones, cada registro de la primera tabla, incluyendo aquellos que no tengan una correspondencia en la segunda, se devuelve junto a cada registro de la segunda tabla, incluyendo aquellos sin correspondencias en la primera. Equivalen a una combinación por la izquierda y una combinación por la derecha.
SELECT campo1, campo2 FROM tabla1 FULL OUTER JOIN tabla2 SELECT * FROM personas p LEFT OUTER JOIN ingenieros i ON i.persona_id = p.persona_id; SELECT * FROM ingenieros i RIGHT OUTER JOIN personas p ON p.persona_id = i.persona_id;
El campo id de la tabla customer y el campo customer de la tabla sales están relacionados. Si les asignaramos el mismo nombre, podríamos utilizar varios métodos de SQL que permiten que las instrucciones JOIN resulten mas sencillas de manejar. Para demostrarlo, vamos a convertir sales.customer en sales.id:
ALTER TABLE sales CHANGE customer id INT;Ahora, como las dos tablas constan de campos con nombres identicos, podemos realizar una combinación natural, que busca campos con nombres iguales sobre los que realizan una unión.
SELECT first_name, surname, value FROM customer NATURAL JOIN sales;Esta sentencia es identica a:
SELECT first_name, surname, value FROM customer INNER JOIN sales ON customer.id=sales.id;Solo existe un campo identico en ambas tablas, pero si hubiera otros, cada uno de ellos se convertiría en parte de la condición de combinación. Las combinaciones naturales también pueden ser por la izquierda o por la derecha. Las siguientes dos intrucciones son didenticas:
SELECT first_name, surname, value FROM customer LEFT JOIN sales ON customer.id=sales.id; SELECT first_name, surname, value FROM customer NATURAL LEFT JOIN sales;La palabra clave USING brinda un mayor control sobre una combinación natural. Si dos tablas constan de varios campos identicos, esta palabra clave permite especificar aquellos que se utilizarán como condiciones de combinación. Por ejemplo, si tomamos dos tablas A y B, con los mismos campos a,b,c,d las siguientes instrucciones resultarán identicas:
SELECT * FORM A LEFT JOIN B USING (a,b,c,d); SELECT * FROM A NATURAL LEFT JOIN B;La palabra clave USING brinda una mayor flexibilidad porque permite utilizar los campos deseados en la combinación. Por ejemplo:
SELECT * FROM A LEFT JOIN B USING (a,b)
Hasta el momento hemos recuperado las filas que aparecen en ambas tablas en las que se establecia una combinación interna. En las combinaciones externas, también devolviamos los registros de una tabla en la que no se encontraban correpsondencias en la segunda. A menudo resulta util realizar la operación inversa y devolver únicamente los resultados encontrados en una tabla pero no en la otra. Para demostrarlo, en primer lugar vamos a agregar un nuevo comercial:
INSERT INTO sales_rep VALUES (5, 'Jomo', 'Ignesund', 10, '2002-11-29', '1968-12-01');A continuación, si realiza una combinación interna, puede recuperar todos los comerciales que hayan realizado una venta:
SELECT DISTINCT first_name, surname FORM sales_rep INNER JOIN sales ON sales_rep=employee_number;Se utiliza la palabra clave DISTINCT para evitar duplicados por que hay comerciales que han realizado más de una venta. Pero la operación inversa también resulta útil. Suponga que su jefe esta bajo con las ventas y ha decidido que van a rodar cabezas. Nos pide que busquemos los comerciales que no han realizado ninguna venta. Puede buscar esta información examinando los comerciales que aparecen en la tabla sales_rep sin una entrada correspondiente en la tabla sales.
SELECT fisrt_name, surname FROM sales_rep LEFT JOIN sales ON sales_rep=employee_number WHERE sales_rep IS NULL,NEcesitará realizar una combinación por la izquierda (externa, no interna) porque sólo las combinaciones externas devuelven todos los registros sin correspondencias (o valores nulos).
El operador UNION permite combinar los resultados de varias instrucciones SELECT en un único conjunto de resultados. Todos los conjuntos de resultados combinados mediante UNION deben tener la misma estructura. Deben tener el mismo número de columnas y las columnas del conjunto de resultados deben tener tipos de datos compatibles. Puede consultar esta liga para más información UNION combina los resultados de diferentes instrucciones SELECT. Cada instrucción debe constar del mismo número de columnas. Para demostrar el uso de esta instrucción, vamos a crear otra tabla que contenga una lista de clientes recibida del antiguo propietario de su establecimiento:
CREATE TABLE old_customer ( id INT, first_name VARCHAR(30), surname VARCHAR(40) ); INSERT INTO old_customer VALUES ( 5432, 'Thulani', 'Salie' ), ( 2342, 'Shahiem', 'Papo' );A continuación, para obtener una lista con todos los clientes, tanto los antiguos como los nuevos, puede utilizar la siguiente instrucción:
SELECT id, fisrt_name, surname FROM old_customer UNION SELECT id, first_name, surname FROM customer;También puede ordenar el resultado de la forma habitual. Sólo debe tener cuidado al decidir si aplicar la cláusula ORDER BY a toda la unión o sólo a una selección.
SELECT id, fisrt_name, surname FROM old_customer UNION SELECT id, first_name, surname FROM customer ORDER BY surname, first_name;Si solo quisieramos ordenar la segunda selección, necesitaremos utilizar parentesis.
SELECT id, fisrt_name, surname FROM old_customer UNION ( SELECT id, first_name, surname FROM customer ORDER BY surname, first_name );De manera predeterminada, la instrucción UNION no devuelve resultados duplicados (de manera similar a la palabra clave DISTINCT). Puede modificar este comportamiento especificado que todos los resultados se devuelvan con la palabra clave ALL:
SELECT id FROM customer UNION ALL SELECT id FROM sales;El uso de UNION requiere cierta reflexión. Puede unir facilmente campos no relacionados siempre y cuando los campos devueltos en cada operación de selección y los tipos de datos sean iguales. MySQL devolvera estos datos sin problemas aunque no tenga mucho sentido.
SELECT id, surname FROM customer UNION ALL SELECT value, sales_rep FROM sales;

Muchas consultas realizan una operación de selección dentro de una selección. El operador IN le permite especificar valores múltiples en una cláusula WHERE. El operador IN es una forma abreviada de múltipes condiciones OR. Ejemplo:
SELECT * FROM clientes WHERE estado IN (SELECT estado FROM sucursales);
Ya sabe como eliminar un registro con la instrucción DELETE. Y ya sabrá que si no utiliza una cláusula WHERE se eliminarán todos los registros. Un problema asociado a la eliminación de registros utilizando este método es que puede resultar muy lento si la tabla es de gran tamaño. Por suerte, existe otra forma de realizar dicha operación. En primer lugar vamos a eliminar todos los registros de la tabla clientes con la instrucción DELETE.
DELETE FROM clientes;La forma más rápida de eliminar estos valores consiste en utilizar la instrucción TRUNCATE. A continuación:
TRUNCATE FROM clientes;Si observas la diferencia entre el resultado de las dos instrucciones, DELETE informa el número de filas que se ha eliminado, mientras que TRUNCATE solo informa sin contar los elementos eliminados.
MySQL consta de una función que permite almacenar valores como variables temporales para poder utilizarlas en una instrucción posterior. En la gran mayoría de los casos se utiliza un lenguaje de programación para realizar este tipo de acciones, pero las variables de MySQL resultan utiles cuando se trabaja en la linea de comandos de MySQL. El valor de la variable se establece con la instrucción SET o en una instrucción SELECT on :=.
El simbolo @ indica que se trata de una variable de MySQL.
SET @resultado = 100/50; SELECT @resultado; +-----+ [@a ] +-----+ [ 2 ] +-----+
SELECT @promedio := AVG(calificacion_final) FROM alumnos; +-----+ [@a ] +-----+ [ 9.8 ] +-----+Las variables de usuario pueden ser cadenas, enteros y números decimales. Se les puede asignar una expresión (excluyendo aquellos lugares en los que se necesiten determinados valores literales, como en la clausula LIMIT). Sin embargo, no se pueden utilizar para sustituir parte de la consulta, como para reemplazar el nombre de una tabla.
SELECT @a:=2 FROM sales WHERE value>10000; SELECT @a; +-----+ [@a ] +-----+ [ NULL] +-----+ SELECT @a:=2 FORM sales WHERE value>2000; +-----+ [@a ] +-----+ [ 2 ] +-----+

SABER - INDICACIONES:
Elabora los modelos relacionales de los ejercicios del 1 al 8 utilizando SQL Server y MySQL

SABER HACER - INDICACIONES:
La evaluación se presentará el día 15 de marzo.
INDICACIONES: Continuando con las funciones incorporadas vistas en la unidad II, descarga el siguiente documento word y completa los recuadros en blanco. La actividad se realiza en equipos. Una vez finalizada elabora estudia las sentencias y sus definiciones por que hay evaluación. Fecha límite de entrega: Viernes 13 de abril de 2018. Después súbela a box.com
Descarga aquí la actividad de las funciones incorporadas
INDICACIONES:
MODELO
Una institución bancaria solicita un modelo relacional hecho en MySQL Workbench donde creen las siguientes tablas y relaciones:
La institución bancaria cuenta con sucursales alrededor de todo el país, cada una de ellas se identifica por un número de sucursal, nombre de sucursal y dirección completa.
Todos los días en las sucursales se atiende clientes en un horario de 8 a.m. a 4 p.m., los clientes solicitan diferentes servicios en la sucursal. Al entrar el cliente al banco se le pregunta qué servicio desea realizar, se le asigna un turno y la persona pasa a la ventanilla que le fue asignada.
En algunos casos, algunos clientes solo realizan depósitos a cuentas terceras, por lo que solo es necesario llevar el número de cuenta o de la tarjeta. Pero si el cliente desea sacar un préstamo es necesario que presente su información personal como número de cliente, su nombre completo, curp, rfc, fecha de nacimiento para poder obtener el resto de su información y determinar si cuenta con buen historial crediticio. En dado caso de que si, se debe verificar qué tipo de préstamo solicita (interés fijo, interés variable, interés mixto).
Los servicios que ofrece el banco son:
INDICACIONES: Viernes 20 de abril, evaluación final sobre todos los temas.